Python将MarkDown转PDF(完美转换HTML,含LaTeX、表格等渲染) |
您所在的位置:网站首页 › markdown 转 html › Python将MarkDown转PDF(完美转换HTML,含LaTeX、表格等渲染) |
Python将MarkDown转PDF(完美转换HTML,含LaTeX、表格等渲染)
|
文章目录
问题描述解决方案引入更多扩展引入数学包网页转PDF封装额外代码行号进度条
参考文献显示效果
问题描述
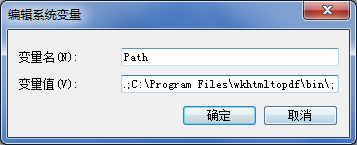
将MarkDown转PDF 本文比较麻烦,还可以尝试 Pandoc 本文全部代码及其CSS下载地址 解决方案 使用 Typora结合 wkhtmltopdf 使用 markdown 库 和 pdfkit 库1. 安装 mdutils pip install markdown pip install pdfkit2. 安装 wkhtmltopdf wkhtmltopdf 下载地址 添加到环境变量 Path 中(可使用绝对路径)
3. 代码 test.md 参考: 作业部落默认 Markdown 模板 import pdfkit from markdown import markdown input_filename = 'test.md' output_filename = 'test.pdf' with open(input_filename, encoding='utf-8') as f: text = f.read() html = markdown(text, output_format='html') # MarkDown转HTML pdfkit.from_string(html, output_filename, options={'encoding': 'utf-8'}) # HTML转PDF # wkhtmltopdf = r'C:\Program Files\wkhtmltopdf\bin\wkhtmltopdf.exe' # 指定wkhtmltopdf # configuration = pdfkit.configuration(wkhtmltopdf=wkhtmltopdf) # pdfkit.from_string(html, output_filename, configuration=configuration, options={'encoding': 'utf-8'}) # HTML转PDF若没有配置环境变量,使用注释里的代码 4. 效果 不支持标注不支持表格不支持LaTeX不支持代码块不支持流程图、序列图、甘特图
test.md |项目|价格|数量| |---|---|---| |计算机|$1600|5| |手机|$12|12| |管线|$1|234|无法正确渲染 引入扩展 tables import pdfkit from markdown import markdown text = '''|项目|价格|数量| |---|---|---| |计算机|$1600|5| |手机|$12|12| |管线|$1|234|''' html = markdown(text, output_format='html', extensions=['tables']) # MarkDown转HTML pdfkit.from_string(html, 'test.pdf', options={'encoding': 'utf-8'}) # HTML转PDF
详细阅读:Available Extensions 引入数学包 HTML 引入 KaTeXmarkdown库启用mdx_math安装 pip install python-markdown-math import pdfkit from markdown import markdown input_filename = 'test.md' output_filename = 'test.pdf' html = '{}' text = '$$E=mc^2$$' text = markdown(text, output_format='html', extensions=['mdx_math']) # MarkDown转HTML html = html.format(text) pdfkit.from_string(html, output_filename, options={'encoding': 'utf-8'}) # HTML转PDF详细阅读:第三方扩展 网页转PDF生成HTML代码效果不完美,可以使用作业部落的导出HTML功能,再转PDF import pdfkit pdfkit.from_file('test.html', 'test.pdf', options={'encoding': 'utf-8'}) # HTML转PDF 封装使用官方扩展和部分第三方扩展 安装库 pip install python-markdown-math pip install pygments pip install pymdown-extensions 下载CSS github-markdown.css 改名为 markdown.csscodehilite.css 生成命令 pygmentize -S default -f html -a .highlight > codehilite.csslinenum.css [data-linenos]:before { content: attr(data-linenos); } tasklist.css .markdown-body .task-list-item { list-style-type: none !important; } .markdown-body .task-list-item input[type="checkbox"] { margin: 0 4px 0.25em -20px; vertical-align: middle; }代码 import os import pdfkit from markdown import markdown from pymdownx import superfences def markdown2pdf(input, output='test.pdf', encoding='utf-8', savehtml=False): html = ''' {} {} ''' with open(input, encoding=encoding) as f: text = f.read() extensions = [ 'toc', # 目录,[toc] 'extra', # 缩写词、属性列表、释义列表、围栏式代码块、脚注、在HTML的Markdown、表格 ] third_party_extensions = [ 'mdx_math', # KaTeX数学公式,$E=mc^2$和$$E=mc^2$$ 'markdown_checklist.extension', # checklist,- [ ]和- [x] 'pymdownx.magiclink', # 自动转超链接, 'pymdownx.caret', # 上标下标, 'pymdownx.superfences', # 多种块功能允许嵌套,各种图表 'pymdownx.betterem', # 改善强调的处理(粗体和斜体) 'pymdownx.mark', # 亮色突出文本 'pymdownx.highlight', # 高亮显示代码 'pymdownx.tasklist', # 任务列表 'pymdownx.tilde', # 删除线 ] extensions.extend(third_party_extensions) extension_configs = { 'mdx_math': { 'enable_dollar_delimiter': True # 允许单个$ }, 'pymdownx.superfences': { "custom_fences": [ { 'name': 'mermaid', # 开启流程图等图 'class': 'mermaid', 'format': superfences.fence_div_format } ] }, 'pymdownx.highlight': { 'linenums': True, # 显示行号 'linenums_style': 'pymdownx-inline' # 代码和行号分开 }, 'pymdownx.tasklist': { 'clickable_checkbox': True, # 任务列表可点击 } } # 扩展配置 title = '.'.join(os.path.basename(input).split('.')[:-1]) text = markdown(text, output_format='html', extensions=extensions, extension_configs=extension_configs) # MarkDown转HTML html = html.format(title, text) print(html) if savehtml: with open(input.replace('.md', '.html'), 'w', encoding=encoding) as f: f.write(html) pdfkit.from_string(html, output, options={'encoding': 'utf-8'}) # HTML转PDF if __name__ == '__main__': markdown2pdf('test.md', 'test.pdf', savehtml=True) print('完成')效果看文末 PS: 缺什么找对应扩展即可,若无可自行编写。原理为MarkDown转HTML转PDF,pdfkit效果并不好,所以效果也有限。可使用 Adobe Acrobat Pro 转换,但流程图等转换依旧不完美。 额外这部分非通用MarkDown 代码行号linenum.md ```python if __name__ == '__main__': print('Hello World!') ``` ```python import math print(math.pi) # 圆周率 ```linenum.css [data-linenos]:before { content: attr(data-linenos); }linenum.py from markdown import markdown filename = 'linenum.md' html = ''' linenum {} ''' encoding = 'utf-8' with open(filename, encoding=encoding) as f: text = f.read() extensions = [ 'pymdownx.superfences', # 多种块功能允许嵌套,各种图表 'pymdownx.highlight' # 高亮显示代码 ] extension_configs = { 'pymdownx.highlight': { 'linenums': True, # 显示行号 'linenums_style': 'pymdownx-inline' # 代码和行号分开 } } # 扩展配置 text = markdown(text, output_format='html', extensions=extensions, extension_configs=extension_configs) # MarkDown转HTML html = html.format(text) print(html) with open(filename.replace('.md', '.html'), 'w', encoding=encoding) as f: f.write(html) # pdfkit.from_string(html, output, options={'encoding': 'utf-8'}) # HTML转PDF print('完成')效果 progressbar.css .progress-label { position: absolute; text-align: center; font-weight: 700; width: 100%; margin: 0; line-height: 1.2rem; white-space: nowrap; overflow: hidden; } .progress-bar { height: 1.2rem; float: left; background-color: #2979ff; } .progress { display: block; width: 100%; margin: 0.5rem 0; height: 1.2rem; background-color: #eeeeee; position: relative; } .progress.thin { margin-top: 0.9rem; height: 0.4rem; } .progress.thin .progress-label { margin-top: -0.4rem; } .progress.thin .progress-bar { height: 0.4rem; } .progress-100plus .progress-bar { background-color: #00e676; } .progress-80plus .progress-bar { background-color: #fbc02d; } .progress-60plus .progress-bar { background-color: #ff9100; } .progress-40plus .progress-bar { background-color: #ff5252; } .progress-20plus .progress-bar { background-color: #ff1744; } .progress-0plus .progress-bar { background-color: #f50057; }progressbar.py from markdown import markdown filename = 'progressbar.md' html = ''' progressbar {} ''' encoding = 'utf-8' with open(filename, encoding=encoding) as f: text = f.read() extensions = [ 'markdown.extensions.attr_list', 'pymdownx.progressbar' ] text = markdown(text, output_format='html', extensions=extensions) # MarkDown转HTML html = html.format(text) print(html) with open(filename.replace('.md', '.html'), 'w', encoding=encoding) as f: f.write(html) # pdfkit.from_string(html, output, options={'encoding': 'utf-8'}) # HTML转PDF print('完成')progressbar.md [=0% "0%"] [=5% "5%"] [=25% "25%"] [=45% "45%"] [=65% "65%"] [=85% "85%"] [=100% "100%"] [=85% "85%"]{: .candystripe} [=100% "100%"]{: .candystripe .candystripe-animate} [=0%]{: .thin} [=5%]{: .thin} [=25%]{: .thin} [=45%]{: .thin} [=65%]{: .thin} [=85%]{: .thin} [=100%]{: .thin}效果 点我对比 作业部落渲染效果
|



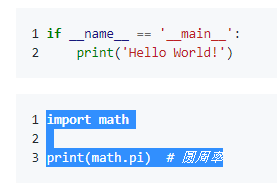 这样直接复制代码不会带有行号
这样直接复制代码不会带有行号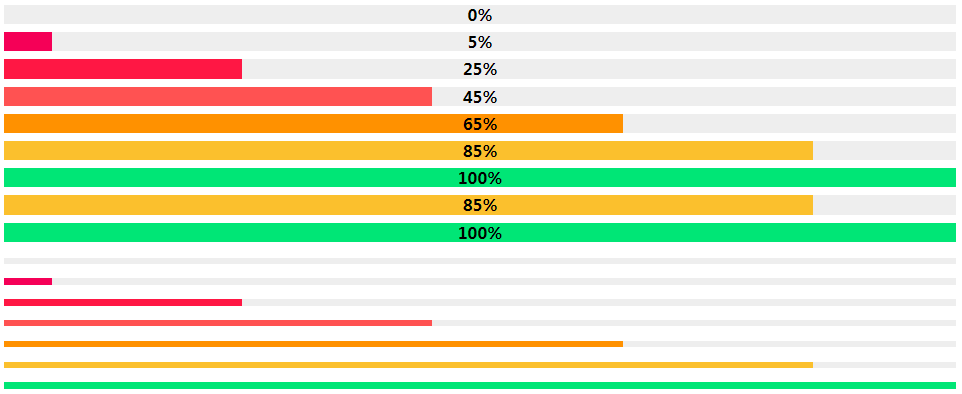
【本文地址】
今日新闻 |
推荐新闻 |